在Kilo Code中使用Ollama
Kilo Code 支持通过 Ollama 在本地运行模型。这提供了隐私保护、离线访问能力,并可能降低成本,但需要更多设置且依赖高性能计算机。
官方网站: https://ollama.com/
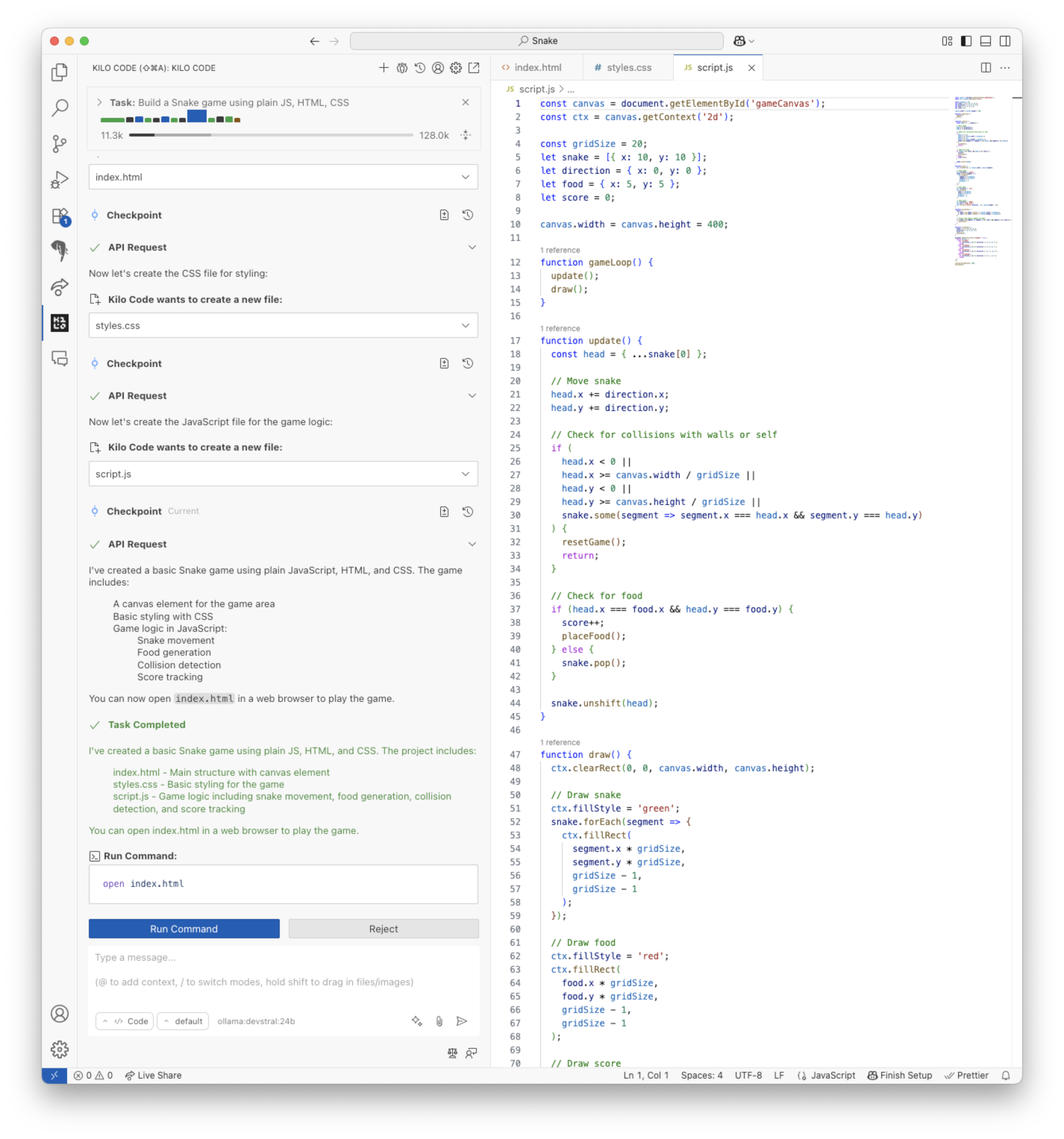
使用 devstral 编写贪吃蛇游戏
管理期望
可以在本地运行的LLM通常比云端托管的LLM(如Claude和GPT)要小得多,因此结果也会逊色不少。 它们更容易陷入循环、无法正确使用工具或在代码中产生语法错误。 要找到合适的提示词通常需要更多的反复试验。 本地运行LLM通常也不够快。 使用简单的提示词、保持对话简短并禁用MCP工具可以提高运行速度。
硬件要求
你需要一块拥有大量显存(24GB或以上)的GPU,或者一台拥有大量统一内存(32GB或以上)的MacBook,才能以良好的速度运行下面讨论的模型。
选择模型
Ollama 支持许多不同的模型。 你可以在 Ollama 网站 上找到可用模型的列表。
对于 Kilo Code 代理,当前推荐使用 qwen3-coder:30b。qwen3-coder:30b 有时无法正确调用工具(相比完整版 qwen3-coder:480b 模型,这个问题更常见)。作为一个混合专家模型,这可能是因为它激活了错误的专家。每当发生这种情况时,尝试更改你的提示词或使用“增强提示”按钮。
qwen3-coder:30b 的替代方案是 devstral:24b。对于 Kilo Code 的其他功能,如增强提示或提交信息生成,较小的模型可能就足够了。
设置 Ollama
要设置 Ollama 以与 Kilo Code 一起使用,请按照以下说明操作。
下载并安装 Ollama
从 Ollama 网站 下载 Ollama 安装程序(或使用你操作系统的包管理器)。按照安装说明操作,然后确保 Ollama 正在运行:
ollama serve
下载模型
要下载模型,请打开第二个终端(ollama serve 需要正在运行)并运行:
ollama pull <model_name>
例如:
ollama pull qwen3-coder:30b
配置上下文长度
默认情况下,Ollama 会将提示截断为非常短的长度,如这里所述。
你需要至少 32k 才能获得不错的结果,但增加上下文长度会增加内存使用量,并可能降低性能,具体取决于你的硬件。 要配置模型,你需要设置其参数并保存一个副本。
加载模型(我们将使用 qwen3-coder:30b 作为示例):
ollama run qwen3-coder:30b
更改上下文大小参数:
/set parameter num_ctx 32768
保存模型并命名为新名称:
/save qwen3-coder-30b-c32k
你也可以设置 OLLAMA_CONTEXT_LENGTH 环境变量,
但不推荐这样做,因为它会改变所有模型的上下文,而且该环境变量需要对 Ollama 服务器和 IDE 都可见。
配置 Kilo Code
- 打开 Kilo Code 侧边栏(
 图标)。
图标)。 - 点击设置齿轮图标()。
- 选择 "Ollama" 作为 API 提供商。
- 选择在上一步中配置的模型。
- (可选)如果你在不同的机器上运行 Ollama,可以配置基础 URL。默认值为
http://localhost:11434。
进一步阅读
有关安装、配置和使用 Ollama 的更多信息,请参阅 Ollama 文档。